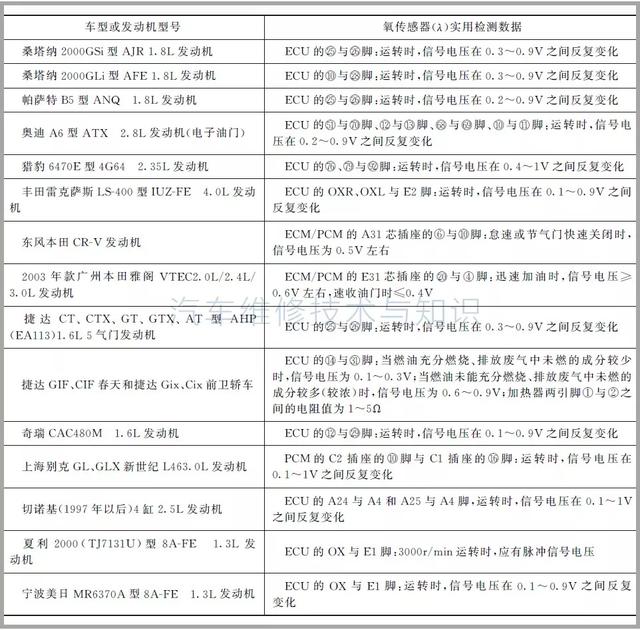
最近生病,经历了半个月,总算是活过来了。
既然没死,那学习就永无止境吧。
今天讲讲在ubuntu中安装pyspider的注意事项吧。
PySpider 是非常方便并且功能强大的爬虫框架,支持多线程爬取、JS动态解析,提供了可操作界面、出错重试、定时爬取等的功能,使用非常人性化,选择在ubuntu中安装也是为了更好的管理和应用。
在安装PySpider之前,需要安装pip,这里使用的是Python3.6,因此安装pip3。

在终端输入以下命令,并输入密码就可以开始进行pip安装:sudo apt install python3-pip其次,还需要安装相关依赖包:
python-dev
python-distribute
libcurl4-openssl-dev
libxml2-dev
libxslt1-dev
pythonlxml
另外,还需要安装pycurl,而pycurl的依赖包有:
libcurl4-gnutls-dev
libghc-gnutls-dev
直接使用apt进行安装即可,如:

安装python-dev包
然后安装pycurl,还有phantomjs
安装pycurl命令如下:
pip install pycurl
安装phantomjs命令如下:
sudo apt install phantomjs
将依赖包都安装完成后,开始安装pyspider:

安装完成了,就可以直接运行Pyspider:
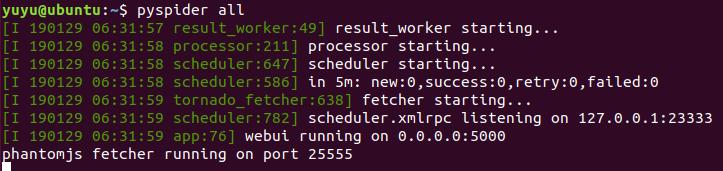
然后打开浏览器,输入:127.0.0.1:5000,就可以打开pyspider界面:
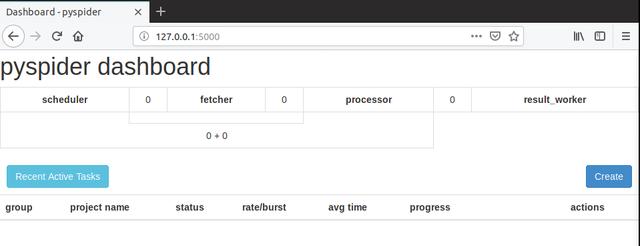
接下来就可以使用pyspider进行爬取数据了,下次我们讲pyspider的使用,谢谢。